Reverse Engineering Gba Video
Abahbob / April 2024 (2759 Words, 16 Minutes)
Background
While looking through games using ADS1.2, a few of them stood out. There are quite a few Game Boy Advance Video titles listed here. For those unaware, GBA Video was a series of GBA cartridges with either TV shows or movies on them. They would have either two 22-minute shows, four 11-minute shows, three 15-minute shows, or an hour and a half movie. Two special titles even had TWO full movies on them, for a full runtime of 2:47:06.
The list of ADS1.2 games only has a few titles on it, and it looks like these only got up to 44 minutes of runtime. Looking into it more, it appears that there are essentially two eras of GBA Video. The first is the ADS era, which uses a completely original compression method for videos. The GCC era actually utilizes Actimagine VX which is used in some DS titles as well.
My particular interest is in the ADS titles, as they are made by the same team that made Winx Club (my other decomp project). There’s quite a lot of overlap between these two, including the video codec that they made. This particular codec is outlined in two patents. The first covers converting from 15-bit pixel information to 24-bit information (bitmap). The second covers the actual video codec, which relies on the implementation of the first.
One of the most interesting aspects of these titles is how they actually work, outside of just the codec. The standard GBA ROM is either 4 or 8 MB large. Some games get upwards of 20MB, but they are definitely outliers. These GBA Video games are 32MB large (with the GCC movies actually being 64MB).
For the rest of this article, I’m going to be looking at Game Boy Advance Video - Dragon Ball GT - Volume 1 (USA).gba.
Technical
ROM Layout
Opening up the ROM in IDA, I initially noticed something very interesting. After loading in my ADS signatures, I noticed repeated library functions. This generally shouldn’t even be possible. After a quick look, I found that there’s actually a ROM within this ROM! I’ll refer to the outer ROM as the BootstrapROM, and the inner ROM as the InternalROM from here on out.
The BootstrapROM is 3668 bytes of code, followed by a data region that contains a simple archive format that contains the following files:
1
2
3
4
5
6
7
commonresources.mmstr 4.7K
jingle.mmstr 1.5M
logo 45K
main.bin 47K
menuresources.mmstr 150K
movie_1.mmstr 16M
movie_2.mmstr 15M
For this, main.bin is our InternalROM. The script I used to extract these files from the archive is:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
import os
import struct
# Adjust these paths as necessary
archive_path = 'archive.sfcd'
output_dir = 'extracted_files'
def read_string(file, length):
return file.read(length).decode('utf-8')
def read_uint16(file):
return struct.unpack('<H', file.read(2))[0]
def read_uint32(file):
return struct.unpack('<I', file.read(4))[0]
def align_to_four_bytes(file):
while file.tell() % 4 != 0:
file.read(1)
def extract_files(archive_path, output_dir):
with open(archive_path, 'rb') as archive_file:
# Validate header
header = read_string(archive_file, 4)
if header != 'SFCD':
raise ValueError('This is not a valid SFCD archive.')
# Read archive metadata
data_offset = read_uint16(archive_file) + 8
data_length = read_uint16(archive_file)
entry_count = read_uint32(archive_file)
print(f"Data Offset: {data_offset}, Data Length: {data_length}, Entry Count: {entry_count}")
os.makedirs(output_dir, exist_ok=True)
# Process each entry
for _ in range(entry_count):
data_size = read_uint32(archive_file)
entry_data_offset = read_uint32(archive_file)
# Read and align the file name
name_bytes = []
while True:
char = archive_file.read(1)
if char == b'\x00':
align_to_four_bytes(archive_file)
break
name_bytes.append(char)
file_name = b''.join(name_bytes).decode('utf-8')
# Save current position and jump to file data
current_pos = archive_file.tell()
archive_file.seek(data_offset + entry_data_offset)
file_data = archive_file.read(data_size)
# Write the file data to a new file
with open(os.path.join(output_dir, file_name), 'wb') as output_file:
output_file.write(file_data)
# Return to the next entry position
archive_file.seek(current_pos)
print(f"Extracted {file_name}")
if __name__ == '__main__':
extract_files(archive_path, output_dir)
print('Extraction complete.')
Here’s the SFCD archive documentation (all types are little endian):
Header: | Offset | Length | Name | Format | | —— | —— | ——————- | —— | |0 |16 |File Identier |ASCII | |16 |16 |File size in bytes |Decimal | |32 |32 |Entry Count |Decimal | |64 |8 |Padding |0x00 |
The header is followed by a table of entries: | Offset | Length | Name | Format | | ——- | ——- | ——————– | ——————– | |0 |32 | File size in bytes |Decimal | |32 |32 | File offset in bytes |Decimal | |64 |Variable | Filename |Null-terminated Ascii | |Variable |Variable | Alignment to 4 bytes |0x00 |
Extracting the InternalROM
Taking a look at the BootstrapROM’s main function, we can see that it extracts the InternalROM to 0x2000000. This represents the GBA’s on-board Work RAM as per gbatek. This makes sense, as it takes the least amount of cycles to read from here, so execution should be fastest. This is where we want to run our most intense code from.
While actually using GDB to debug the workings of this, I noticed some peculiar things about the memory mapping though. We can see a number of different memory regions being referenced for code execution. This includes 0x02000000 (IWRAM), 0x03000000 (EWRAM), 0x08000000 (Gamepak ROM), and 0x0A000000 (Gamepak ROM Wait State 1). Analyzing the memory at these regions, it appears that the latter portion of the InternalROM is actually loaded into EWRAM at some point. This is notable as EWRAM is only a 16-bit bus, so we’re primarily looking at THUMB instructions. This is notable because the main decompression function is actually loaded into EWRAM, where I would’ve expected it to be ran from IWRAM.
Investigating mmstr files
One of the main reasons I started this sidequest is because both Winx Club and these GBA Video titles share this .mmstr archive format. I’ve got some working code to handle extracting from it, although I will soon be re-writing it into a proper library as this was my first pass for reversing.
The initial quirk with these files is that they use a small encoding for filenames. I’m not exactly sure why they do this, it doesn’t seem to serve any real purpose aside from some minor obfuscation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
def decode_from_bytestring(encoded_bytes):
# Reverse mapping for special characters, from encoded byte values back to characters
reverse_special_char_mapping = {
-1: ' ', -2: '\n', 63: '.', 64: ',', 65: ':', 66: ';',
67: '!', 68: '?', 69: '&', 70: '(', 71: ')', 72: '\'',
73: '-', 74: '/', 75: '+', 76: '\xA9', 77: '\x99',
78: '_', 79: '$', 80: '"', 81: '<', 82: '>', 83: '*',
84: '=', 85: '\xAE', 86: '#', 87: '@', 88: '%', 89: '\\',
90: '~', 91: '[', 92: ']',
}
# Convert negative keys to their correct byte representation in Python (0-255 range)
reverse_special_char_mapping = {key & 0xFF: value for key, value in reverse_special_char_mapping.items()}
# Initialize an empty string for the result
result = ""
for byte in encoded_bytes:
if byte in reverse_special_char_mapping:
result += reverse_special_char_mapping[byte]
elif 1 <= byte <= 10: # Encoded Digits
result += chr(byte + 47)
elif 11 <= byte <= 36: # Encoded Lowercase letters
result += chr(byte + 86)
elif 37 <= byte <= 62: # Encoded Uppercase letters
result += chr(byte + 28)
else:
# Directly append other characters (this may not be necessary unless there are byte values not covered above)
result += chr(byte)
return result
Here’s the mmstr documentation:
Header: | Offset | Length | Name | Format | | —— | —— | ——————- | —— | |0 |32 | Unknown | | |32 |32 | Entry Count |Decimal |
The header is followed by the entries (once again little endian): | Offset | Length | Name | Format | | ——- | ——- | ——————– | ——————– | |0 |28 | File Size in bytes | Decimal | |28 |4 | File Type | Decimal | |32 |32 | Unknown | | |64 |Variable | File Name | Encoded ASCII | |Variable |Variable | Align to 4 bytes | 0x00 |
It’s worth noting that there’s no entry table, they’re all sequential. Also, later code expects these files to include their header. The File Size includes the length of the header. Additionally, some of these archives appear to not use filenames, and exclusively use the index of the entry. In that case, the filenames will be garbage and only the size and file type are cleanly decoded.
Compression
Working on reverse engineering compression is brand new to me, so there have been a ton of pitfalls that I’ve fallen into. I was able to relatively quickly identify the main function that is decompressing images, which I’ve included the IDA psuedocode output of here. It’s a whopping 1123 lines, which is painful. My approach was to re-implement it in Python to simplify debugging. After a day of work, I arrived at this. It’s not pretty, as it’s an initial pass at attempting to maintain the same code structure as the original C. This strategy was crucial to debugging.
My process for debugging was as follows:
- Identify a compressed file that I wanted to use for testing.
- Find a way to identify when it’s being decompressed.
- Step through the code in IDA and VSCode, and ensure that our variables are maintaining the same state at the same time.
For identifying which file was being decompressed, I was able to use dword38 as a good conditional breakpoint. This is stored with in the compressed file right before the main image data, and is always set on entry into the function.
There are quite a few pain points to address here. First, we’re converting from using pointers to using arrays of bytes. Thankfully the original code maintained the pointer offsets and didn’t shift them around, otherwise we’d have to diverge quite a bit. For initial testing I set the arrays to be excessively large, but I was able to identify their intended lengths through trial and error.
Another pain point that I knew going in is Python’s handling of integers. C/C++ has size limits on integers, while Python will let them grow to be quite large. In the original code, there are cases where the code relies on integer overflow/underflows, so we have to use & 0xFFFFFFFF liberally in our Python code. I’d tried using numpy’s types to handle this, but apparently that’s a feature they’re going to deprecate going forward.
It’s difficult to maintain code of this complexity with so little understanding of exactly what it does. It goes against every instinct to maintain bad variable names and repetitive code, but it drastically improves the debugging experience. I’m looking forward to being able to do a full refactor.
On the bright side, I can confirm that my code is working for images in both GBA Video and Winx Club. This includes all of the GBA Video background and UI images.
A look at visuals
The GBA has a few different rendering modes. The relevant mode we’re going to be looking at is mode 3, which is full bitmap. The usage of this mode is actually quite interesting, as it’s typically used for still images. For GBA Video, the entire game is rendered in BG Mode 3. This is notable because there’s no support for transparency or tiles. All of the menus are actually rendered to a single bitmap, even though the components are stored as individual images (or videos in the case of chapter select).
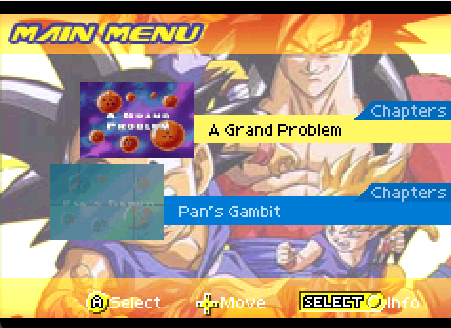
Looking at the above image, there are a number of images. We have the background, the font, and each of the buttons for the controls. The images for the videos are actually being updated and playing a short preview of the video. What’s interesting is that the entire visual we have here is stored as just a single bitmap in Background 2, so all updates are done by selectively updating just the relevant part in VRAM.
Video
We’ve now reached where I’m currently at, so the following is going to be a lot of my observations and won’t have much concrete backing to it. I’d originally believed that the above code was from the first patent above, but it doesn’t actually fit that bill. After looking over the patent, I don’t think it’s actually being used here at all. This seems to be a unique compression algorithm that is used in conjunction with the patent.
Following execution while a video is being played reveals that there are actually two objects that are being used for the decompression. Each frame, one (or both) objects will call the decompression method. Neither output actually resembles bitmaps though. This leads to the second patent. Fig 5 in the patent is the relevant diagram here. My current suspicion is that one of these objects represents the decompression of the codebook, while the other represents decompressing the indices.
Analysing this process is exceptionally tedious. We have code jumping between ROM, IWRAM, and EWRAM. We also have C++ objects calling virtual functions (which thanks to ADS are not easily statically traceable with IDA). While I’m confident I can reverse it, it will take some time.